Pre-train ELECTRA for Spanish from Scratch
ELECTRA is another member of the Transformer pre-training method family, whose previous members such as BERT, GPT-2, RoBERTa have achieved many state-of-the-...

ELECTRA is another member of the Transformer pre-training method family, whose previous members such as BERT, GPT-2, RoBERTa have achieved many state-of-the-...
In an effort to make BERTSUM lighter and faster for low-resource devices, I fine-tuned DistilBERT and MobileBERT, two lite versions of BERT on CNN/DailyMail ...
In this blog post, to really leverage the power of transformer models, we will fine-tune SpanBERTa for a named-entity recognition task.
Self-training methods with transformer models have achieved state-of-the-art performance on most NLP tasks. However, because training them is computationally...
Convolutional Neural Networks (CNN) were originally invented for computer vision (CV) and now are the building block of state-of-the-art CV models. One of th...
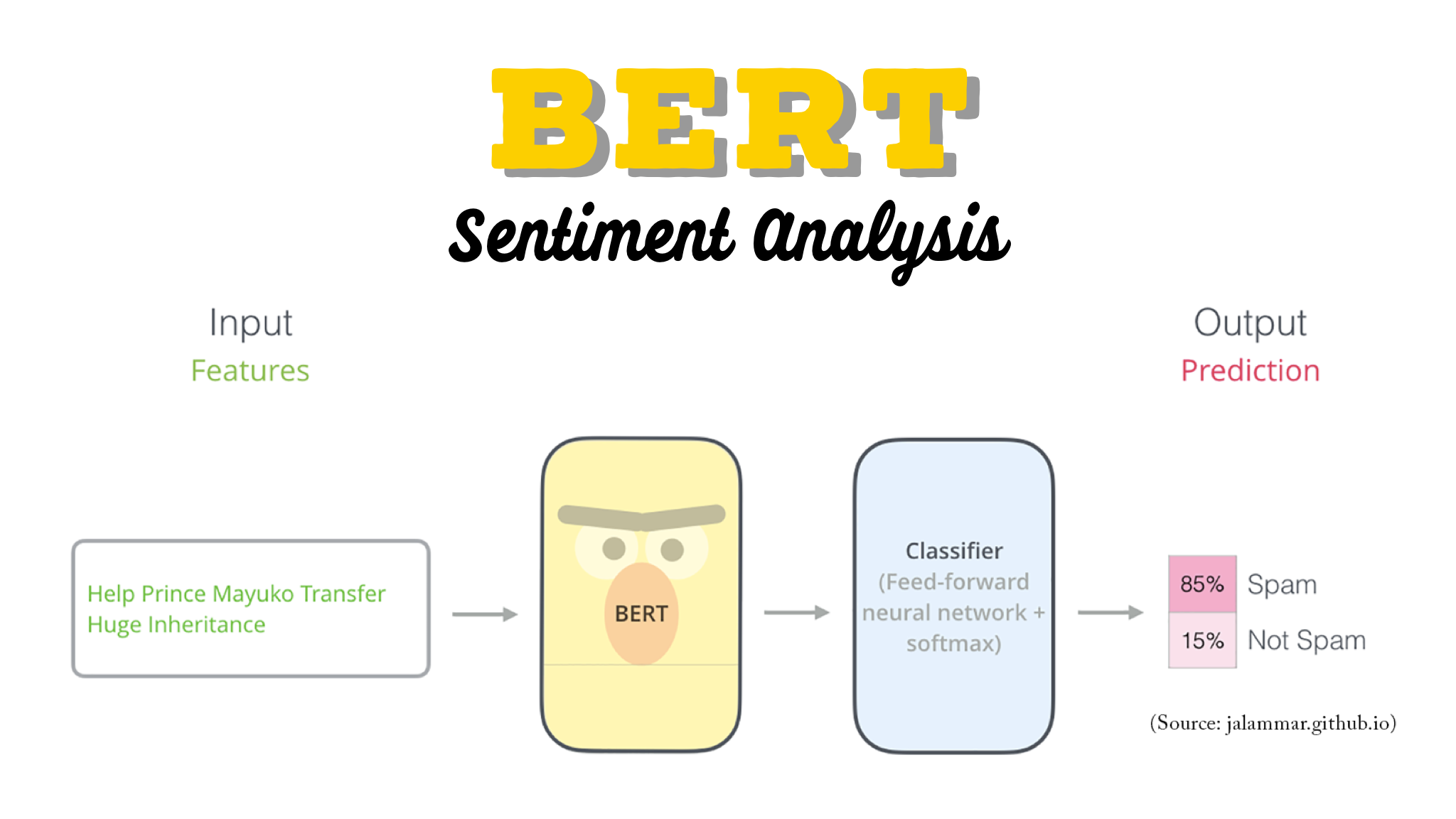
One of the most biggest milestones in the evolution of NLP recently is the release of Google’s BERT, which is described as the beginning of a new era in NLP....
ELECTRA is another member of the Transformer pre-training method family, whose previous members such as BERT, GPT-2, RoBERTa have achieved many state-of-the-...
In an effort to make BERTSUM lighter and faster for low-resource devices, I fine-tuned DistilBERT and MobileBERT, two lite versions of BERT on CNN/DailyMail ...
In this blog post, to really leverage the power of transformer models, we will fine-tune SpanBERTa for a named-entity recognition task.
Self-training methods with transformer models have achieved state-of-the-art performance on most NLP tasks. However, because training them is computationally...
One of the most biggest milestones in the evolution of NLP recently is the release of Google’s BERT, which is described as the beginning of a new era in NLP....
We are going to build a world-class image classifier using the fastai library to classify 11 popular Vietnamese dishes.
Convolutional Neural Networks (CNN) were originally invented for computer vision (CV) and now are the building block of state-of-the-art CV models. One of th...
In the early days of my journey in data science a year ago, I spent most of my time reading articles on Towards Data Science to create my own Data Science ro...
In the early days of my journey in data science a year ago, I spent most of my time reading articles on Towards Data Science to create my own Data Science ro...
In the early days of my journey in data science a year ago, I spent most of my time reading articles on Towards Data Science to create my own Data Science ro...
In this blog post, to really leverage the power of transformer models, we will fine-tune SpanBERTa for a named-entity recognition task.
We are going to build a world-class image classifier using the fastai library to classify 11 popular Vietnamese dishes.
In an effort to make BERTSUM lighter and faster for low-resource devices, I fine-tuned DistilBERT and MobileBERT, two lite versions of BERT on CNN/DailyMail ...
ELECTRA is another member of the Transformer pre-training method family, whose previous members such as BERT, GPT-2, RoBERTa have achieved many state-of-the-...