
SpanBERTa: Pre-train RoBERTa Language Model for Spanish from Scratch

Introduction
Self-training methods with transformer models have achieved state-of-the-art performance on most NLP tasks. However, because training them is computationally expensive, most currently available pretrained transformer models are only for English. Therefore, to improve performance on NLP tasks in our projects on Spanish, my team at Skim AI decided to train a RoBERTa language model for Spanish from scratch and call it SpanBERTa.
SpanBERTa has the same size as RoBERTa-base. We followed RoBERTa’s training schema to train the model on 18 GB of OSCAR’s Spanish corpus in 8 days using 4 Tesla P100 GPUs.
In this blog post, we will walk through an end-to-end process to train a BERT-like language model from scratch using transformers and tokenizers libraries by Hugging Face. There is also a Google Colab notebook to run the codes in this article directly. You can also modify the notebook accordingly to train a BERT-like model for other languages or fine-tune it on your customized dataset.
Before moving on, I want to express a huge thank to the Hugging Face team for making state-of-the-art NLP models accessible for everyone.
Setup
1. Install Dependencies
%%capture
!pip uninstall -y tensorflow
!pip install transformers
2. Data
We pretrained SpanBERTa on OSCAR’s Spanish corpus. The full size of the dataset is 150 GB and we used a portion of 18 GB to train.
In this example, for simplicity, we will use a dataset of Spanish movie subtitles from OpenSubtitles. This dataset has a size of 5.4 GB and we will train on a subset of ~300 MB.
import os
# Download and unzip movie substitle dataset
if not os.path.exists('data/dataset.txt'):
!wget "https://object.pouta.csc.fi/OPUS-OpenSubtitles/v2016/mono/es.txt.gz" -O dataset.txt.gz
!gzip -d dataset.txt.gz
!mkdir data
!mv dataset.txt data
--2020-04-06 15:53:04-- https://object.pouta.csc.fi/OPUS-OpenSubtitles/v2016/mono/es.txt.gz
Resolving object.pouta.csc.fi (object.pouta.csc.fi)... 86.50.254.18, 86.50.254.19
Connecting to object.pouta.csc.fi (object.pouta.csc.fi)|86.50.254.18|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1859673728 (1.7G) [application/gzip]
Saving to: ‘dataset.txt.gz’
dataset.txt.gz 100%[===================>] 1.73G 17.0MB/s in 1m 46s
2020-04-06 15:54:51 (16.8 MB/s) - ‘dataset.txt.gz’ saved [1859673728/1859673728]
# Total number of lines and some random lines
!wc -l data/dataset.txt
!shuf -n 5 data/dataset.txt
179287150 data/dataset.txt
Sabes, pensé que tenías más pelotas que para enfrentarme a través de mi hermano.
Supe todos los encantamientos en todas las lenguas de los Elfos hombres y Orcos.
Anteriormente en Blue Bloods:
Y quiero que prometas que no habrá ningún trato con Daniel Stafford.
Fue comiquísimo.
# Get a subset of first 10,000,000 lines for training
TRAIN_SIZE = 10000000 #@param {type:"integer"}
!(head -n $TRAIN_SIZE data/dataset.txt) > data/train.txt
# Get a subset of next 10,000 lines for validation
VAL_SIZE = 10000 #@param {type:"integer"}
!(sed -n {TRAIN_SIZE + 1},{TRAIN_SIZE + VAL_SIZE}p data/dataset.txt) > data/dev.txt
3. Train a Tokenizer
The original BERT implementation uses a WordPiece tokenizer with a vocabulary of 32K subword units. This method, however, can introduce “unknown” tokens when processing rare words.
In this implementation, we use a byte-level BPE tokenizer with a vocabulary of 50,265 subword units (same as RoBERTa-base). Using byte-level BPE makes it possible to learn a subword vocabulary of modest size that can encode any input without getting “unknown” tokens.
Because ByteLevelBPETokenizer produces 2 files ["vocab.json", "merges.txt"] while BertWordPieceTokenizer produces only 1 file vocab.txt, it will cause an error if we use BertWordPieceTokenizer to load outputs of a BPE tokenizer.
%%time
from tokenizers import ByteLevelBPETokenizer
path = "data/train.txt"
# Initialize a tokenizer
tokenizer = ByteLevelBPETokenizer()
# Customize training
tokenizer.train(files=path,
vocab_size=50265,
min_frequency=2,
special_tokens=["<s>", "<pad>", "</s>", "<unk>", "<mask>"])
# Save files to disk
!mkdir -p "models/roberta"
tokenizer.save("models/roberta")
CPU times: user 1min 37s, sys: 1.02 s, total: 1min 38s
Wall time: 1min 38s
Super fast! It takes only 2 minutes to train on 10 million lines.

Traing Language Model from Scratch
1. Model Architecture
RoBERTa has exactly the same architecture as BERT. The only differences are:
- RoBERTa uses a Byte-Level BPE tokenizer with a larger subword vocabulary (50k vs 32k).
- RoBERTa implements dynamic word masking and drops next sentence prediction task.
- RoBERTa’s training hyperparameters.
Other architecture configurations can be found in the documentation (RoBERTa, BERT).
import json
config = {
"architectures": [
"RobertaForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 514,
"model_type": "roberta",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"type_vocab_size": 1,
"vocab_size": 50265
}
with open("models/roberta/config.json", 'w') as fp:
json.dump(config, fp)
tokenizer_config = {"max_len": 512}
with open("models/roberta/tokenizer_config.json", 'w') as fp:
json.dump(tokenizer_config, fp)
2. Training Hyperparameters
| Hyperparam | BERT-base | RoBERTa-base |
|---|---|---|
| Sequence Length | 128, 512 | 512 |
| Batch Size | 256 | 8K |
| Peak Learning Rate | 1e-4 | 6e-4 |
| Max Steps | 1M | 500K |
| Warmup Steps | 10K | 24K |
| Weight Decay | 0.01 | 0.01 |
| Adam \(\epsilon\) | 1e-6 | 1e-6 |
| Adam \(\beta_1\) | 0.9 | 0.9 |
| Adam \(\beta_2\) | 0.999 | 0.98 |
| Gradient Clipping | 0.0 | 0.0 |
Note the batch size when training RoBERTa is 8000. Therefore, although RoBERTa-base was trained for 500K steps, its training computational cost is 16 times that of BERT-base. In the RoBERTa paper, it is shown that training with large batches improves perplexity for the masked language modeling objective, as well as end-task accuracy. Larger batch size can be obtained by tweaking gradient_accumulation_steps.
Due to computational constraint, we followed BERT-base’s training schema and trained our SpanBERTa model using 4 Tesla P100 GPUs for 200K steps in 8 days.
3. Start Training
We will train our model from scratch using run_language_modeling.py, a script provided by Hugging Face, which will preprocess, tokenize the corpus and train the model on Masked Language Modeling task. The script is optimized to train on a single big corpus. Therefore, if your dataset is large and you want to split it to train sequentially, you will need to modify the script, or be ready to get a monster machine with high memory.
!wget -c https://raw.githubusercontent.com/chriskhanhtran/spanish-bert/master/run_language_modeling.py
Important Arguments
--line_by_lineWhether distinct lines of text in the dataset are to be handled as distinct sequences. If each line in your dataset is long and has ~512 tokens or more, you should use this setting. If each line is short, the default text preprocessing will concatenate all lines, tokenize them and slit tokenized outputs into blocks of 512 tokens. You can also split your datasets into small chunks and preprocess them separately. 3GB of text will take ~50 minutes to process with the defaultTextDatasetclass.--should_continueWhether to continue from latest checkpoint in output_dir.--model_name_or_pathThe model checkpoint for weights initialization. Leave None if you want to train a model from scratch.--mlmTrain with masked-language modeling loss instead of language modeling.--config_name, --tokenizer_nameOptional pretrained config and tokenizer name or path if not the same as model_name_or_path. If both are None, initialize a new config.--per_gpu_train_batch_sizeBatch size per GPU/CPU for training. Choose the largest number you can fit on your GPUs. You will see an error if your batch size is too large.--gradient_accumulation_stepsNumber of updates steps to accumulate before performing a backward/update pass. You can use this trick to increase batch size. For example, ifper_gpu_train_batch_size = 16andgradient_accumulation_steps = 4, your total train batch size will be 64.--overwrite_output_dirOverwrite the content of the output directory.--no_cuda, --fp16, --fp16_opt_levelArguments for training on GPU/CPU.- Other arguments are model paths and training hyperparameters.
It’s highly recommended to include model type (eg. “roberta”, “bert”, “gpt2” etc.) in the model path because the script uses the AutoModels class to guess the model’s configuration using pattern matching on the provided path.
# Model paths
MODEL_TYPE = "roberta" #@param ["roberta", "bert"]
MODEL_DIR = "models/roberta" #@param {type: "string"}
OUTPUT_DIR = "models/roberta/output" #@param {type: "string"}
TRAIN_PATH = "data/train.txt" #@param {type: "string"}
EVAL_PATH = "data/dev.txt" #@param {type: "string"}
For this example, we will train for only 25 steps on a Tesla P4 GPU provided by Colab.
!nvidia-smi
Mon Apr 6 15:59:35 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.64.00 Driver Version: 418.67 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P4 Off | 00000000:00:04.0 Off | 0 |
| N/A 31C P8 7W / 75W | 0MiB / 7611MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
# Command line
cmd = """python run_language_modeling.py \
--output_dir {output_dir} \
--model_type {model_type} \
--mlm \
--config_name {config_name} \
--tokenizer_name {tokenizer_name} \
{line_by_line} \
{should_continue} \
{model_name_or_path} \
--train_data_file {train_path} \
--eval_data_file {eval_path} \
--do_train \
{do_eval} \
{evaluate_during_training} \
--overwrite_output_dir \
--block_size 512 \
--max_step 25 \
--warmup_steps 10 \
--learning_rate 5e-5 \
--per_gpu_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--weight_decay 0.01 \
--adam_epsilon 1e-6 \
--max_grad_norm 100.0 \
--save_total_limit 10 \
--save_steps 10 \
--logging_steps 2 \
--seed 42
"""
# Arguments for training from scratch. I turn off evaluate_during_training,
# line_by_line, should_continue, and model_name_or_path.
train_params = {
"output_dir": OUTPUT_DIR,
"model_type": MODEL_TYPE,
"config_name": MODEL_DIR,
"tokenizer_name": MODEL_DIR,
"train_path": TRAIN_PATH,
"eval_path": EVAL_PATH,
"do_eval": "--do_eval",
"evaluate_during_training": "",
"line_by_line": "",
"should_continue": "",
"model_name_or_path": "",
}
If you are training on a virtual machine, you can install tensorboard to monitor the training process. Here is our Tensorboard for training SpanBERTa.
pip install tensorboard==2.1.0
tensorboard dev upload --logdir runs
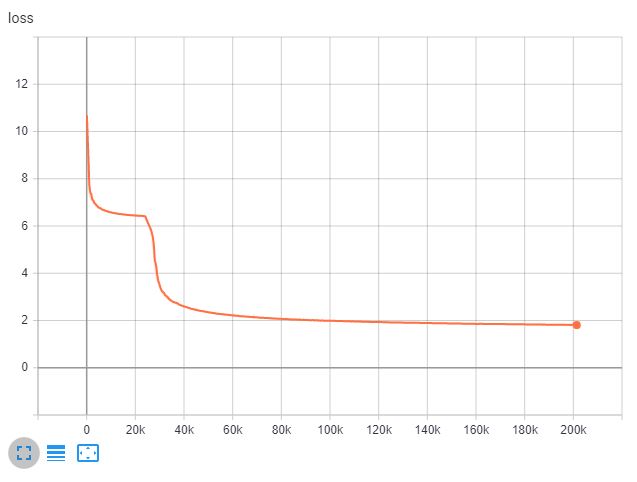
After 200k steps, the loss reached 1.8 and the perplexity reached 5.2.
Now let’s start training!
!{cmd.format(**train_params)}
04/06/2020 15:59:41 - WARNING - __main__ - Process rank: -1, device: cuda, n_gpu: 1, distributed training: False, 16-bits training: False
04/06/2020 15:59:41 - INFO - transformers.configuration_utils - loading configuration file models/roberta/config.json
04/06/2020 15:59:41 - INFO - transformers.configuration_utils - Model config RobertaConfig {
04/06/2020 15:59:41 - INFO - transformers.configuration_utils - loading configuration file models/roberta/config.json
04/06/2020 15:59:41 - INFO - transformers.configuration_utils - Model config RobertaConfig {
04/06/2020 15:59:41 - INFO - transformers.tokenization_utils - Model name 'models/roberta' not found in model shortcut name list (roberta-base, roberta-large, roberta-large-mnli, distilroberta-base, roberta-base-openai-detector, roberta-large-openai-detector). Assuming 'models/roberta' is a path, a model identifier, or url to a directory containing tokenizer files.
04/06/2020 15:59:41 - INFO - transformers.tokenization_utils - loading file models/roberta/vocab.json
04/06/2020 15:59:41 - INFO - transformers.tokenization_utils - loading file models/roberta/merges.txt
04/06/2020 15:59:41 - INFO - transformers.tokenization_utils - loading file models/roberta/tokenizer_config.json
04/06/2020 15:59:41 - INFO - __main__ - Training new model from scratch
04/06/2020 15:59:55 - INFO - __main__ - Training/evaluation parameters Namespace(adam_epsilon=1e-06, block_size=512, cache_dir=None, config_name='models/roberta', device=device(type='cuda'), do_eval=True, do_train=True, eval_all_checkpoints=False, eval_data_file='data/dev.txt', evaluate_during_training=False, fp16=False, fp16_opt_level='O1', gradient_accumulation_steps=4, learning_rate=5e-05, line_by_line=False, local_rank=-1, logging_steps=2, max_grad_norm=100.0, max_steps=25, mlm=True, mlm_probability=0.15, model_name_or_path=None, model_type='roberta', n_gpu=1, no_cuda=False, num_train_epochs=1.0, output_dir='models/roberta/output', overwrite_cache=False, overwrite_output_dir=True, per_gpu_eval_batch_size=4, per_gpu_train_batch_size=4, save_steps=10, save_total_limit=10, seed=42, server_ip='', server_port='', should_continue=False, tokenizer_name='models/roberta', train_data_file='data/train.txt', warmup_steps=10, weight_decay=0.01)
04/06/2020 15:59:55 - INFO - __main__ - Creating features from dataset file at data
04/06/2020 16:04:43 - INFO - __main__ - Saving features into cached file data/roberta_cached_lm_510_train.txt
04/06/2020 16:04:46 - INFO - __main__ - ***** Running training *****
04/06/2020 16:04:46 - INFO - __main__ - Num examples = 165994
04/06/2020 16:04:46 - INFO - __main__ - Num Epochs = 1
04/06/2020 16:04:46 - INFO - __main__ - Instantaneous batch size per GPU = 4
04/06/2020 16:04:46 - INFO - __main__ - Total train batch size (w. parallel, distributed & accumulation) = 16
04/06/2020 16:04:46 - INFO - __main__ - Gradient Accumulation steps = 4
04/06/2020 16:04:46 - INFO - __main__ - Total optimization steps = 25
Epoch: 0% 0/1 [00:00<?, ?it/s]
Iteration: 0% 0/41499 [00:00<?, ?it/s][A
Iteration: 0% 1/41499 [00:01<13:18:02, 1.15s/it][A
Iteration: 0% 2/41499 [00:01<11:26:47, 1.01it/s][A
Iteration: 0% 3/41499 [00:02<10:10:30, 1.13it/s][A
Iteration: 0% 4/41499 [00:03<9:38:10, 1.20it/s] [A
Iteration: 0% 5/41499 [00:03<8:52:44, 1.30it/s][A
Iteration: 0% 6/41499 [00:04<8:22:47, 1.38it/s][A
Iteration: 0% 7/41499 [00:04<8:00:55, 1.44it/s][A
Iteration: 0% 8/41499 [00:05<8:03:40, 1.43it/s][A
Iteration: 0% 9/41499 [00:06<7:46:57, 1.48it/s][A
Iteration: 0% 10/41499 [00:06<7:35:35, 1.52it/s][A
Epoch: 0% 0/1 [01:25<?, ?it/s]
04/06/2020 16:06:11 - INFO - __main__ - global_step = 26, average loss = 9.355212138249325
04/06/2020 16:06:11 - INFO - __main__ - Saving model checkpoint to models/roberta/output
04/06/2020 16:06:18 - INFO - transformers.modeling_utils - loading weights file models/roberta/output/pytorch_model.bin
04/06/2020 16:06:23 - INFO - __main__ - Creating features from dataset file at data
04/06/2020 16:06:23 - INFO - __main__ - Saving features into cached file data/roberta_cached_lm_510_dev.txt
04/06/2020 16:06:23 - INFO - __main__ - ***** Running evaluation *****
04/06/2020 16:06:23 - INFO - __main__ - Num examples = 156
04/06/2020 16:06:23 - INFO - __main__ - Batch size = 4
Evaluating: 100% 39/39 [00:08<00:00, 4.41it/s]
04/06/2020 16:06:32 - INFO - __main__ - ***** Eval results *****
04/06/2020 16:06:32 - INFO - __main__ - perplexity = tensor(6077.6812)
4. Predict Masked Words
After training your language model, you can upload and share your model with the community. We have uploaded our SpanBERTa model to Hugging Face’s server. Before evaluating the model on downstream tasks, let’s see how it has learned to fill masked words given a context.
%%capture
%%time
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="chriskhanhtran/spanberta",
tokenizer="chriskhanhtran/spanberta"
)
I pick a sentence from Wikipedia’s article about COVID-19.
The original sentence is “Lavarse frecuentemente las manos con agua y jabón,” meaning “Frequently wash your hands with soap and water.”
The masked word is “jabón” (soap) and the top 5 predictions are soap, salt, steam, lemon and vinegar. It is interesting that the model somehow learns that we should wash our hands with things that can kill bacteria or contain acid.
fill_mask("Lavarse frecuentemente las manos con agua y <mask>.")
[{'score': 0.6469631195068359,
'sequence': '<s> Lavarse frecuentemente las manos con agua y jabón.</s>',
'token': 18493},
{'score': 0.06074320897459984,
'sequence': '<s> Lavarse frecuentemente las manos con agua y sal.</s>',
'token': 619},
{'score': 0.029787985607981682,
'sequence': '<s> Lavarse frecuentemente las manos con agua y vapor.</s>',
'token': 11079},
{'score': 0.026410052552819252,
'sequence': '<s> Lavarse frecuentemente las manos con agua y limón.</s>',
'token': 12788},
{'score': 0.017029203474521637,
'sequence': '<s> Lavarse frecuentemente las manos con agua y vinagre.</s>',
'token': 18424}]
Conclusion
We have walked through how to train a BERT language model for Spanish from scratch and seen that the model has learned properties of the language by trying to predict masked words given a context. You can also follow this article to fine-tune a pretrained BERT-like model on your customized dataset.
Next, we will implement the pretrained models on downstream tasks including Sequence Classification, NER, POS tagging, and NLI, as well as compare the model’s performance with some non-BERT models.
Stay tuned for our next posts!



Leave a comment