

A Complete Guide to CNN for Sentence Classification with PyTorch
Convolutional Neural Networks (CNN) were originally invented for computer vision and now are the building blocks of state-of-the-art CV models. One of the earliest applications of CNN in Natural Language Processing was introduced in the paper Convolutional Neural Networks for Sentence Classification (Kim, 2014). With the same idea as in computer vision, CNN model is used as an feature extractor that encodes semantic features of sentences before these features are fed to a classifier.
With only a simple one-layer CNN trained on top of pretrained word vectors and little hyperparameter tuning, the model achieves excellent results on multiple sentence-level classification tasks. CNN models are now used widely in other NLP tasks such as translation and question answering as a part of a more complex architecture.
When implementing the original paper (Kim, 2014) in PyTorch, I needed to put many pieces together to complete the project. This article serves as a complete guide to CNN for sentence classification tasks accompanied with advice for practioners. It will cover:
- Tokenizing and building vocabuilary from text data
- Loading pretrained fastText word vectors and creating embedding layer for fine-tuning
- Building and training CNN model with PyTorch
- Advice for practitioners
- Bonus: Using Skorch as a scikit-like wrapper for PyTorch’s Deep Learning models
Reference:
- Convolutional Neural Networks for Sentence Classification (Kim, 2014).
- A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification (Zhang, 2015).
- Advances in Pre-Training Distributed Word Representations (Mikolov, 2018).
1. Setup
1.1. Import Libraries
import os
import re
from tqdm import tqdm
import numpy as np
import pandas as pd
import nltk
nltk.download("all")
import matplotlib.pyplot as plt
import torch
%matplotlib inline
1.2. Download Datasets
The dataset we will use is Movie Review (MR), a sentence polarity dataset from (Pang and Lee, 2005). The dataset has 5331 positive and 5331 negative processed sentences/snippets.
URL = 'https://www.cs.cornell.edu/people/pabo/movie-review-data/rt-polaritydata.tar.gz'
# Download Datasets
!wget -P 'Data/' $URL
# Unzip
!tar xvzf 'Data/rt-polaritydata.tar.gz' -C 'Data/'
def load_text(path):
"""Load text data, lowercase text and save to a list."""
with open(path, 'rb') as f:
texts = []
for line in f:
texts.append(line.decode(errors='ignore').lower().strip())
return texts
# Load files
neg_text = load_text('Data/rt-polaritydata/rt-polarity.neg')
pos_text = load_text('Data/rt-polaritydata/rt-polarity.pos')
# Concatenate and label data
texts = np.array(neg_text + pos_text)
labels = np.array([0]*len(neg_text) + [1]*len(pos_text))
1.3. Download fastText Word Vectors
The pretrained word vectors used in the original paper were trained by word2vec (Mikolov et al., 2013) on 100 billion tokens of Google News. In this tutorial, we will use fastText pretrained word vectors (Mikolov et al., 2017), trained on 600 billion tokens on Common Crawl. fastText is an upgraded version of word2vec and outperforms other state-of-the-art methods by a large margin.
The code below will download fastText pretrained vectors. Using Google Colab, the running time is approximately 3min 30s.
%%time
URL = "https://dl.fbaipublicfiles.com/fasttext/vectors-english/crawl-300d-2M.vec.zip"
FILE = "fastText"
if os.path.isdir(FILE):
print("fastText exists.")
else:
!wget -P $FILE $URL
!unzip $FILE/crawl-300d-2M.vec.zip -d $FILE
crawl-300d-2M.vec.z 100%[===================>] 1.42G 23.8MB/s in 62s
2020-02-01 00:40:43 (23.3 MB/s) - ‘fastText/crawl-300d-2M.vec.zip’ saved [1523785255/1523785255]
Archive: fastText/crawl-300d-2M.vec.zip
inflating: fastText/crawl-300d-2M.vec
1.4. Use GPU for Training
Google Colab offers free GPUs and TPUs. Since we’ll be training a large neural network it’s best to utilize these features.
A GPU can be added by going to the menu and selecting:
Runtime -> Change runtime type -> Hardware accelerator: GPU
Then we need to run the following cell to specify the GPU as the device.
if torch.cuda.is_available():
device = torch.device("cuda")
print(f'There are {torch.cuda.device_count()} GPU(s) available.')
print('Device name:', torch.cuda.get_device_name(0))
else:
print('No GPU available, using the CPU instead.')
device = torch.device("cpu")
There are 1 GPU(s) available.
Device name: Tesla T4
2. Data Preparation
To prepare our text data for training, first we need to tokenize our sentences and build a vocabulary dictionary word2idx, which will later be used to convert our tokens into indexes and build an embedding layer.
So, what is an embedding layer?
An embedding layer serves as a look-up table which takes words’ indexes in the vocabulary as input and output word vectors. Hence, the embedding layer has shape \((N, d)\) where \(N\) is the size of the vocabulary and \(d\) is the embedding dimension. In order to fine-tune pretrained word vectors, we need to create an embedding layer in our nn.Module class. Our input to the model will then be input_ids, which is tokens’ indexes in the vocabulary.
2.1. Tokenize
The function tokenize will tokenize our sentences, build a vocabulary and find the maximum sentence length. The function encode will take outputs of tokenize as inputs, perform sentence padding and return input_ids as a numpy array.
from nltk.tokenize import word_tokenize
from collections import defaultdict
def tokenize(texts):
"""Tokenize texts, build vocabulary and find maximum sentence length.
Args:
texts (List[str]): List of text data
Returns:
tokenized_texts (List[List[str]]): List of list of tokens
word2idx (Dict): Vocabulary built from the corpus
max_len (int): Maximum sentence length
"""
max_len = 0
tokenized_texts = []
word2idx = {}
# Add <pad> and <unk> tokens to the vocabulary
word2idx['<pad>'] = 0
word2idx['<unk>'] = 1
# Building our vocab from the corpus starting from index 2
idx = 2
for sent in texts:
tokenized_sent = word_tokenize(sent)
# Add `tokenized_sent` to `tokenized_texts`
tokenized_texts.append(tokenized_sent)
# Add new token to `word2idx`
for token in tokenized_sent:
if token not in word2idx:
word2idx[token] = idx
idx += 1
# Update `max_len`
max_len = max(max_len, len(tokenized_sent))
return tokenized_texts, word2idx, max_len
def encode(tokenized_texts, word2idx, max_len):
"""Pad each sentence to the maximum sentence length and encode tokens to
their index in the vocabulary.
Returns:
input_ids (np.array): Array of token indexes in the vocabulary with
shape (N, max_len). It will the input of our CNN model.
"""
input_ids = []
for tokenized_sent in tokenized_texts:
# Pad sentences to max_len
tokenized_sent += ['<pad>'] * (max_len - len(tokenized_sent))
# Encode tokens to input_ids
input_id = [word2idx.get(token) for token in tokenized_sent]
input_ids.append(input_id)
return np.array(input_ids)
2.2. Load Pretrained Vectors
We will load the pretrained vectors for each token in our vocabulary. For tokens with no pretraiend vectors, we will initialize random word vectors with the same dimension and variance.
from tqdm import tqdm_notebook
def load_pretrained_vectors(word2idx, fname):
"""Load pretrained vectors and create embedding layers.
Args:
word2idx (Dict): Vocabulary built from the corpus
fname (str): Path to pretrained vector file
Returns:
embeddings (np.array): Embedding matrix with shape (N, d) where N is
the size of word2idx and d is embedding dimension
"""
print("Loading pretrained vectors...")
fin = open(fname, 'r', encoding='utf-8', newline='\n', errors='ignore')
n, d = map(int, fin.readline().split())
# Initilize random embeddings
embeddings = np.random.uniform(-0.25, 0.25, (len(word2idx), d))
embeddings[word2idx['<pad>']] = np.zeros((d,))
# Load pretrained vectors
count = 0
for line in tqdm_notebook(fin):
tokens = line.rstrip().split(' ')
word = tokens[0]
if word in word2idx:
count += 1
embeddings[word2idx[word]] = np.array(tokens[1:], dtype=np.float32)
print(f"There are {count} / {len(word2idx)} pretrained vectors found.")
return embeddings
Now let’s put above steps together.
# Tokenize, build vocabulary, encode tokens
print("Tokenizing...\n")
tokenized_texts, word2idx, max_len = tokenize(texts)
input_ids = encode(tokenized_texts, word2idx, max_len)
# Load pretrained vectors
embeddings = load_pretrained_vectors(word2idx, "fastText/crawl-300d-2M.vec")
embeddings = torch.tensor(embeddings)
Tokenizing...
Loading pretrained vectors...
There are 18526 / 20286 pretrained vectors found.
2.3. Create PyTorch DataLoader
We will create an iterator for our dataset using the torch DataLoader class. This will help save on memory during training and boost the training speed. The batch size used in the paper is 50.
from torch.utils.data import (TensorDataset, DataLoader, RandomSampler,
SequentialSampler)
def data_loader(train_inputs, val_inputs, train_labels, val_labels,
batch_size=50):
"""Convert train and validation sets to torch.Tensors and load them to
DataLoader.
"""
# Convert data type to torch.Tensor
train_inputs, val_inputs, train_labels, val_labels =\
tuple(torch.tensor(data) for data in
[train_inputs, val_inputs, train_labels, val_labels])
# Specify batch_size
batch_size = 50
# Create DataLoader for training data
train_data = TensorDataset(train_inputs, train_labels)
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)
# Create DataLoader for validation data
val_data = TensorDataset(val_inputs, val_labels)
val_sampler = SequentialSampler(val_data)
val_dataloader = DataLoader(val_data, sampler=val_sampler, batch_size=batch_size)
return train_dataloader, val_dataloader
We will use 90% of the dataset for training and 10% for validation.
from sklearn.model_selection import train_test_split
# Train Test Split
train_inputs, val_inputs, train_labels, val_labels = train_test_split(
input_ids, labels, test_size=0.1, random_state=42)
# Load data to PyTorch DataLoader
train_dataloader, val_dataloader = \
data_loader(train_inputs, val_inputs, train_labels, val_labels, batch_size=50)
3. Model
CNN Architecture
The picture below is the illustration of the CNN architecture that we are going to build with three filter sizes: 2, 3, and 4, each of which has 2 filters.
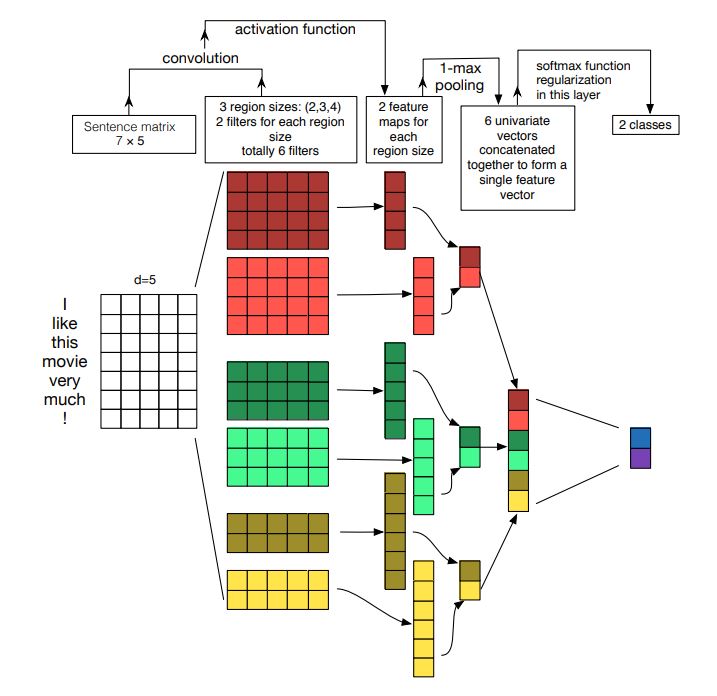 CNN Architecture (Source: Zhang, 2015)
CNN Architecture (Source: Zhang, 2015)
# Sample configuration:
filter_sizes = [2, 3, 4]
num_filters = [2, 2, 2]
Suppose that we are classifying the sentence “I like this movie very much!” (\(N = 7\) tokens) and the dimensionality of word vectors is \(d=5\). After applying the embedding layer on the input token ids, the sample sentence is presented as a 2D tensor with shape (7, 5) like an image.
\[\mathrm{x_{emb}} \quad \in \mathbb{R}^{7 \times 5}\]We then use 1-dimesional convolution to extract features from the sentence. In this example, we have 6 filters in total, and each filter has shape \((f_i, d)\) where \(f_i\) is the filter size for \(i \in \{1,...,6\}\). Each filter will then scan over \(\mathrm{x_{emb}}\) and return a feature map:
\[\mathrm{x_{conv_ i} = Conv1D(x_{emb})} \quad \in \mathbb{R}^{N-f_i+1}\]Next, we apply the ReLU activation to \(\mathrm{x_{conv_{i}}}\) and use max-over-time-pooling to reduce each feature map to a single scalar. Then we concatenate these scalars into a vector which will be fed to a fully connected layer to compute the final scores for our classes (logits).
\[\mathrm{x_{pool_i} = MaxPool(ReLU(x_{conv_i}))} \quad \in \mathbb{R}\] \[\mathrm{x_{fc} = \texttt{concat}(x_{pool_i})} \quad \in \mathbb{R}^6\]The idea here is that each filter will capture different semantic signals in the sentence (e.g., happiness, humor, politics, anger…) and max-pooling will record only the strongest signal over the sentence. This logic makes sense because humans also perceive the sentiment of a sentence based on its strongest semantic signal.
Finally, we use a fully connected layer with the weight matrix \(\mathbf{W_{fc}} \in \mathbb{R}^{2 \times 6}\) and dropout to compute \(\mathrm{logits}\), which is a vector of length 2 that keeps the scores for our two classes.
\[\mathrm{logits = Dropout(\mathbf{W_{fc}}x_{fc})} \in \mathbb{R}^2\]An in-depth explanation of CNN can be found in this article and this video.
3.1. Create CNN Model
For simplicity, the model above has very small configurations. The final model will have the same architecture but be much bigger:
| Description | Values |
|---|---|
| input word vectors | fastText |
| embedding size | 300 |
| filter sizes | (3, 4, 5) |
| num filters | (100, 100, 100) |
| activation | ReLU |
| pooling | 1-max pooling |
| dropout rate | 0.5 |
import torch
import torch.nn as nn
import torch.nn.functional as F
class CNN_NLP(nn.Module):
"""An 1D Convulational Neural Network for Sentence Classification."""
def __init__(self,
pretrained_embedding=None,
freeze_embedding=False,
vocab_size=None,
embed_dim=300,
filter_sizes=[3, 4, 5],
num_filters=[100, 100, 100],
num_classes=2,
dropout=0.5):
"""
The constructor for CNN_NLP class.
Args:
pretrained_embedding (torch.Tensor): Pretrained embeddings with
shape (vocab_size, embed_dim)
freeze_embedding (bool): Set to False to fine-tune pretraiend
vectors. Default: False
vocab_size (int): Need to be specified when not pretrained word
embeddings are not used.
embed_dim (int): Dimension of word vectors. Need to be specified
when pretrained word embeddings are not used. Default: 300
filter_sizes (List[int]): List of filter sizes. Default: [3, 4, 5]
num_filters (List[int]): List of number of filters, has the same
length as `filter_sizes`. Default: [100, 100, 100]
n_classes (int): Number of classes. Default: 2
dropout (float): Dropout rate. Default: 0.5
"""
super(CNN_NLP, self).__init__()
# Embedding layer
if pretrained_embedding is not None:
self.vocab_size, self.embed_dim = pretrained_embedding.shape
self.embedding = nn.Embedding.from_pretrained(pretrained_embedding,
freeze=freeze_embedding)
else:
self.embed_dim = embed_dim
self.embedding = nn.Embedding(num_embeddings=vocab_size,
embedding_dim=self.embed_dim,
padding_idx=0,
max_norm=5.0)
# Conv Network
self.conv1d_list = nn.ModuleList([
nn.Conv1d(in_channels=self.embed_dim,
out_channels=num_filters[i],
kernel_size=filter_sizes[i])
for i in range(len(filter_sizes))
])
# Fully-connected layer and Dropout
self.fc = nn.Linear(np.sum(num_filters), num_classes)
self.dropout = nn.Dropout(p=dropout)
def forward(self, input_ids):
"""Perform a forward pass through the network.
Args:
input_ids (torch.Tensor): A tensor of token ids with shape
(batch_size, max_sent_length)
Returns:
logits (torch.Tensor): Output logits with shape (batch_size,
n_classes)
"""
# Get embeddings from `input_ids`. Output shape: (b, max_len, embed_dim)
x_embed = self.embedding(input_ids).float()
# Permute `x_embed` to match input shape requirement of `nn.Conv1d`.
# Output shape: (b, embed_dim, max_len)
x_reshaped = x_embed.permute(0, 2, 1)
# Apply CNN and ReLU. Output shape: (b, num_filters[i], L_out)
x_conv_list = [F.relu(conv1d(x_reshaped)) for conv1d in self.conv1d_list]
# Max pooling. Output shape: (b, num_filters[i], 1)
x_pool_list = [F.max_pool1d(x_conv, kernel_size=x_conv.shape[2])
for x_conv in x_conv_list]
# Concatenate x_pool_list to feed the fully connected layer.
# Output shape: (b, sum(num_filters))
x_fc = torch.cat([x_pool.squeeze(dim=2) for x_pool in x_pool_list],
dim=1)
# Compute logits. Output shape: (b, n_classes)
logits = self.fc(self.dropout(x_fc))
return logits
3.2. Optimizer
To train Deep Learning models, we need to define a loss function and minimize this loss. We’ll use back-propagation to compute gradients and use an optimization algorithm (ie. Gradient Descent) to minimize the loss. The original paper used the Adadelta optimizer.
import torch.optim as optim
def initilize_model(pretrained_embedding=None,
freeze_embedding=False,
vocab_size=None,
embed_dim=300,
filter_sizes=[3, 4, 5],
num_filters=[100, 100, 100],
num_classes=2,
dropout=0.5,
learning_rate=0.01):
"""Instantiate a CNN model and an optimizer."""
assert (len(filter_sizes) == len(num_filters)), "filter_sizes and \
num_filters need to be of the same length."
# Instantiate CNN model
cnn_model = CNN_NLP(pretrained_embedding=pretrained_embedding,
freeze_embedding=freeze_embedding,
vocab_size=vocab_size,
embed_dim=embed_dim,
filter_sizes=filter_sizes,
num_filters=num_filters,
num_classes=2,
dropout=0.5)
# Send model to `device` (GPU/CPU)
cnn_model.to(device)
# Instantiate Adadelta optimizer
optimizer = optim.Adadelta(cnn_model.parameters(),
lr=learning_rate,
rho=0.95)
return cnn_model, optimizer
3.3. Training Loop
For each epoch, the code below will perform a forward step to compute the Cross Entropy loss, a backward step to compute gradients and use the optimizer to update weights/parameters. At the end of each epoch, the loss on training data and the accuracy over the validation data will be printed to help us keep track of the model’s performance. The code is heavily annotated with detailed explanations.
import random
import time
# Specify loss function
loss_fn = nn.CrossEntropyLoss()
def set_seed(seed_value=42):
"""Set seed for reproducibility."""
random.seed(seed_value)
np.random.seed(seed_value)
torch.manual_seed(seed_value)
torch.cuda.manual_seed_all(seed_value)
def train(model, optimizer, train_dataloader, val_dataloader=None, epochs=10):
"""Train the CNN model."""
# Tracking best validation accuracy
best_accuracy = 0
# Start training loop
print("Start training...\n")
print(f"{'Epoch':^7} | {'Train Loss':^12} | {'Val Loss':^10} | {\
'Val Acc':^9} | {'Elapsed':^9}")
print("-"*60)
for epoch_i in range(epochs):
# =======================================
# Training
# =======================================
# Tracking time and loss
t0_epoch = time.time()
total_loss = 0
# Put the model into the training mode
model.train()
for step, batch in enumerate(train_dataloader):
# Load batch to GPU
b_input_ids, b_labels = tuple(t.to(device) for t in batch)
# Zero out any previously calculated gradients
model.zero_grad()
# Perform a forward pass. This will return logits.
logits = model(b_input_ids)
# Compute loss and accumulate the loss values
loss = loss_fn(logits, b_labels)
total_loss += loss.item()
# Perform a backward pass to calculate gradients
loss.backward()
# Update parameters
optimizer.step()
# Calculate the average loss over the entire training data
avg_train_loss = total_loss / len(train_dataloader)
# =======================================
# Evaluation
# =======================================
if val_dataloader is not None:
# After the completion of each training epoch, measure the model's
# performance on our validation set.
val_loss, val_accuracy = evaluate(model, val_dataloader)
# Track the best accuracy
if val_accuracy > best_accuracy:
best_accuracy = val_accuracy
# Print performance over the entire training data
time_elapsed = time.time() - t0_epoch
print(f"{epoch_i + 1:^7} | {avg_train_loss:^12.6f} | {\
val_loss:^10.6f} | {val_accuracy:^9.2f} | {time_elapsed:^9.2f}")
print("\n")
print(f"Training complete! Best accuracy: {best_accuracy:.2f}%.")
def evaluate(model, val_dataloader):
"""After the completion of each training epoch, measure the model's
performance on our validation set.
"""
# Put the model into the evaluation mode. The dropout layers are disabled
# during the test time.
model.eval()
# Tracking variables
val_accuracy = []
val_loss = []
# For each batch in our validation set...
for batch in val_dataloader:
# Load batch to GPU
b_input_ids, b_labels = tuple(t.to(device) for t in batch)
# Compute logits
with torch.no_grad():
logits = model(b_input_ids)
# Compute loss
loss = loss_fn(logits, b_labels)
val_loss.append(loss.item())
# Get the predictions
preds = torch.argmax(logits, dim=1).flatten()
# Calculate the accuracy rate
accuracy = (preds == b_labels).cpu().numpy().mean() * 100
val_accuracy.append(accuracy)
# Compute the average accuracy and loss over the validation set.
val_loss = np.mean(val_loss)
val_accuracy = np.mean(val_accuracy)
return val_loss, val_accuracy
4. Evaluation
In the original paper, the author tried different variations of the model.
- CNN-rand: The baseline model where the embedding layer is randomly initialized and then updated during training.
- CNN-static: A model with pretrained vectors. However, the embedding layer is freezed during training.
- CNN-non-static: Same as above but the embedding layers is fine-tuned during training.
We will experiment with all 3 variations and compare their performance. Below is the report of our results and the original paper’s results.
| Model | Kim’s results | Our results |
|---|---|---|
| CNN-rand | 76.1 | 74.2 |
| CNN-static | 81.0 | 82.7 |
| CNN-non-static | 81.5 | 84.4 |
Randomness could cause the difference in the results. I think the reason for the improvement in our results is that we used fastText pretrained vectors, which are of higher quality than word2vec vectors that the author used.
# CNN-rand: Word vectors are randomly initialized.
set_seed(42)
cnn_rand, optimizer = initilize_model(vocab_size=len(word2idx),
embed_dim=300,
learning_rate=0.25,
dropout=0.5)
train(cnn_rand, optimizer, train_dataloader, val_dataloader, epochs=20)
Start training...
Epoch | Train Loss | Val Loss | Val Acc | Elapsed
------------------------------------------------------------
1 | 0.682544 | 0.653227 | 62.22 | 1.50
2 | 0.622080 | 0.616504 | 65.22 | 1.41
3 | 0.546976 | 0.574917 | 69.30 | 1.43
4 | 0.473106 | 0.559976 | 69.21 | 1.43
5 | 0.397637 | 0.541240 | 72.47 | 1.44
6 | 0.322112 | 0.530545 | 71.93 | 1.43
7 | 0.258854 | 0.513072 | 72.92 | 1.43
8 | 0.204417 | 0.534012 | 73.74 | 1.43
9 | 0.157654 | 0.533650 | 74.01 | 1.44
10 | 0.129191 | 0.542072 | 74.19 | 1.44
11 | 0.104160 | 0.561548 | 73.56 | 1.45
12 | 0.083750 | 0.560357 | 73.10 | 1.47
13 | 0.067199 | 0.565875 | 73.10 | 1.45
14 | 0.061943 | 0.591892 | 73.83 | 1.44
15 | 0.047678 | 0.615021 | 73.38 | 1.44
16 | 0.043667 | 0.609918 | 73.47 | 1.45
17 | 0.038222 | 0.624876 | 73.74 | 1.43
18 | 0.037270 | 0.636214 | 73.83 | 1.44
19 | 0.032148 | 0.635478 | 73.19 | 1.46
20 | 0.027427 | 0.636196 | 73.56 | 1.42
Training complete! Best accuracy: 74.19%.
# CNN-static: fastText pretrained word vectors are used and freezed during training.
set_seed(42)
cnn_static, optimizer = initilize_model(pretrained_embedding=embeddings,
freeze_embedding=True,
learning_rate=0.25,
dropout=0.5)
train(cnn_static, optimizer, train_dataloader, val_dataloader, epochs=20)
Start training...
Epoch | Train Loss | Val Loss | Val Acc | Elapsed
------------------------------------------------------------
1 | 0.587050 | 0.473927 | 76.93 | 0.82
2 | 0.453002 | 0.432967 | 79.39 | 0.71
3 | 0.389261 | 0.417466 | 80.11 | 0.74
4 | 0.345526 | 0.417371 | 80.93 | 0.81
5 | 0.284621 | 0.403670 | 81.47 | 0.83
6 | 0.242149 | 0.406981 | 81.93 | 0.81
7 | 0.190178 | 0.460115 | 79.93 | 0.76
8 | 0.155375 | 0.421258 | 82.20 | 0.84
9 | 0.118369 | 0.436616 | 82.02 | 0.80
10 | 0.095217 | 0.443634 | 81.83 | 0.79
11 | 0.078958 | 0.447452 | 82.11 | 0.76
12 | 0.063665 | 0.504030 | 81.20 | 0.83
13 | 0.047461 | 0.457974 | 82.02 | 0.77
14 | 0.043035 | 0.485016 | 82.11 | 0.70
15 | 0.035299 | 0.479483 | 82.11 | 0.82
16 | 0.028384 | 0.498936 | 82.19 | 0.79
17 | 0.024328 | 0.521321 | 82.37 | 0.76
18 | 0.024897 | 0.511377 | 82.74 | 0.74
19 | 0.019988 | 0.530753 | 81.93 | 0.79
20 | 0.017251 | 0.546499 | 82.20 | 0.85
Training complete! Best accuracy: 82.74%.
# CNN-non-static: fastText pretrained word vectors are fine-tuned during training.
set_seed(42)
cnn_non_static, optimizer = initilize_model(pretrained_embedding=embeddings,
freeze_embedding=False,
learning_rate=0.25,
dropout=0.5)
train(cnn_non_static, optimizer, train_dataloader, val_dataloader, epochs=20)
Start training...
Epoch | Train Loss | Val Loss | Val Acc | Elapsed
------------------------------------------------------------
1 | 0.586136 | 0.471964 | 77.21 | 2.08
2 | 0.448910 | 0.428012 | 80.03 | 2.11
3 | 0.381136 | 0.409408 | 81.29 | 2.09
4 | 0.332936 | 0.411652 | 80.75 | 2.10
5 | 0.267999 | 0.397631 | 82.02 | 2.10
6 | 0.223944 | 0.399833 | 81.29 | 2.11
7 | 0.168644 | 0.452024 | 81.29 | 2.10
8 | 0.132921 | 0.442039 | 81.65 | 2.09
9 | 0.097992 | 0.457295 | 81.84 | 2.09
10 | 0.079037 | 0.458124 | 82.38 | 2.09
11 | 0.061001 | 0.459572 | 83.74 | 2.09
12 | 0.047450 | 0.535106 | 81.29 | 2.08
13 | 0.037088 | 0.491504 | 84.37 | 2.10
14 | 0.031085 | 0.503522 | 83.11 | 2.08
15 | 0.025401 | 0.512804 | 84.01 | 2.10
16 | 0.020165 | 0.532516 | 84.19 | 2.11
17 | 0.017053 | 0.545771 | 83.83 | 2.08
18 | 0.017567 | 0.540735 | 84.20 | 2.09
19 | 0.013829 | 0.567102 | 82.47 | 2.09
20 | 0.013072 | 0.594407 | 82.20 | 2.08
Training complete! Best accuracy: 84.37%.
5. Test Model
Let’s test our CNN-non-static model on some examples.
def predict(text, model=cnn_non_static.to("cpu"), max_len=62):
"""Predict probability that a review is positive."""
# Tokenize, pad and encode text
tokens = word_tokenize(text.lower())
padded_tokens = tokens + ['<pad>'] * (max_len - len(tokens))
input_id = [word2idx.get(token, word2idx['<unk>']) for token in padded_tokens]
# Convert to PyTorch tensors
input_id = torch.tensor(input_id).unsqueeze(dim=0)
# Compute logits
logits = model.forward(input_id)
# Compute probability
probs = F.softmax(logits, dim=1).squeeze(dim=0)
print(f"This review is {probs[1] * 100:.2f}% positive.")
Our model can easily regconize reviews with strong negative signals. On samples that have mixed feelings but positive sentiment overvall, our model also gets excellent results.
predict("All of friends slept while watching this movie. But I really enjoyed it.")
predict("I have waited so long for this movie. I am now so satisfied and happy.")
predict("This movie is long and boring.")
predict("I don't like the ending.")
This review is 61.22% positive.
This review is 94.68% positive.
This review is 0.01% positive.
This review is 4.03% positive.
6. Advice for Practitioners
In A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification (Zhang, 2015), the authors conducted a sensitivity analysis of the above CNN architecture by running it many different sets of hyperparameters. Based on main empirical findings of the research, below are some advice for practioners to choose hyperparameters when applying this architecture for sentence classification tasks:
- Input word vectors: Using pretrained word vectors such as word2vec, Glove (or fastText in our implementation) yields much better results than using one-hot vectors or randomly initialized vectors.
- Filter region size can have a large effect on performance, and should be tuned. A reasonable range might be 1~10. For example, using
filter_size=[7]andnum_filters=[400]yields the best result in the MR dataset. - Number of feature maps: try values from 100 to 600 for each filter region size.
- Activation funtions: ReLu and tanh are the best candidates.
- Pooling: Use 1-max pooling.
- Regularization: When increasing number of feature maps, try imposing stronger regularization, e.g. a dropout rate larger than 0.5.
Bonus: Skorch: A Scikit-like Library for PyTorch Modules
If you find the training loop in PyTorch intimidating with a lot of steps and wonder why those steps aren’t wrapped in a function like model.fit() and model.predict() in scikit-learn library. Actually it is something I like in PyTorch. It allows me to manipulate my codes to add extra customizations during training such as clipping gradients and updating learning rates. In addition, because I build my model and training loop block by block, when my model runs into errors, I can navigate the bugs faster. However, when I need to deploy a baseline model quickly, writing an entire training loop is really a burden. It’s when I come to skorch.
skorch is “a scikit-learn compatible neural network library that wraps PyTorch.” There is no need to create DataLoader or write a training/evaluation loop. All you need to do is defining the model and optimizer as in the code below, then a simple net.fit(X, y) is enough.
skorch does not only make it neat and fast to train your Deep Learning models, it also provides powerful support. You can specify callbacks parameters to define early stopping and checkpoint saving. You can also combine skorch model with scikit-learn methods to do cross-validation and hyperparameter tuning with grid-search. Please check out the documentation to explore more powerful functions in this library.
!pip install skorch
from skorch import NeuralNetClassifier
from skorch.helper import predefined_split
from skorch.callbacks import EarlyStopping, Checkpoint, LoadInitState
from skorch.dataset import CVSplit, Dataset
# Specify validation set
val_dataset = Dataset(val_inputs, val_labels)
# Specify callbacks and checkpoints
cp = Checkpoint(monitor='valid_acc_best', dirname='exp1')
callbacks = [
('early_stop', EarlyStopping(monitor='valid_acc', patience=5, lower_is_better=False)),
cp
]
net = NeuralNetClassifier(
# Module
module=CNN_NLP,
module__pretrained_embedding=embeddings,
module__freeze_embedding=False,
module__dropout=0.5,
# Optimizer
criterion=nn.CrossEntropyLoss,
optimizer=optim.Adadelta,
optimizer__lr=0.25,
optimizer__rho=0.95,
# Others
max_epochs=20,
batch_size=50,
train_split=predefined_split(val_dataset),
iterator_train__shuffle=True,
warm_start=False,
callbacks=callbacks,
device=device
)
skorch also prints training results in a very nice table. My training loop in section 3 is inspired by this format. When model (checkpoints) are saved, you can see the + sign in column cp.
set_seed(42)
_ = net.fit(np.array(train_inputs), train_labels)
valid_acc_best = np.max(net.history[:, 'valid_acc'])
print(f"Training complete! Best accuracy: {valid_acc_best * 100:.2f}%")
epoch train_loss valid_acc valid_loss cp dur
------- ------------ ----------- ------------ ---- ------
1 0.5862 0.7741 0.4727 + 2.2838
2 0.4481 0.7901 0.4385 + 2.2232
3 0.3849 0.7938 0.4369 + 2.2337
4 0.3242 0.8285 0.3940 + 2.2340
5 0.2787 0.8257 0.3951 2.2225
6 0.2156 0.8285 0.3958 2.2006
7 0.1714 0.8144 0.4410 2.2059
8 0.1336 0.8332 0.4100 + 2.2174
9 0.0950 0.8266 0.4295 2.2214
10 0.0738 0.8238 0.4489 2.1938
11 0.0596 0.8304 0.4705 2.1988
12 0.0476 0.8266 0.4769 2.2083
Stopping since valid_acc has not improved in the last 5 epochs.
Training complete! Best accuracy: 83.32%
As Deep Learning model can overfit training data quickly, it’s important to save our model when it fits validation data just right. After training, we can load our model from the last checkpoint to make predictions.
# Load parameters from checkpoint
net.load_params(checkpoint=cp)
predict("All of friends slept while watching this movie. But I really enjoyed it.", model=net)
predict("I have waited so long for this movie. I am now so satisfied and happy.", model=net)
predict("This movie is long and boring.", model=net)
predict("I don't like the ending.", model=net)
This review is 67.25% positive.
This review is 61.38% positive.
This review is 0.12% positive.
This review is 19.14% positive.
Conclusion
Before the rise of huge and complicated models using Transformer architecture, a simple CNN architecture with one layer of convolution can yield excellent performance on sentence classification tasks. The model can take advantages of unsupervised pre-training of word vectors to improve overall performance. Improvements can be made in this architecture by increasing the number of CNN layers or using sub-word model (using BPE tokenizer and fastText pretrained sub-word vectors). Because of its speed, we can use the CNN model as a strong baseline before trying more complicated models such as BERT.
Thank you for staying with me to this point. If interested, you can check out other articles in my NLP tutorial series:



Leave a comment